Das Thema Performance ist sehr wichtig für BI-Systeme. Es gibt mehrere Möglichkeiten, die Abfragegeschwindigkeit zu verbessern. Eine dieser Möglichkeiten ist die Erstellung von Aggregationen in Analysis Services.
Wenn mit der Entwicklung eines neuen Projektes für SQL Server Analysis Services (kurz: SSAS) begonnen wird, erwartet man von den erstellten Cubes eine hervorragende Abfragegeschwindigkeit. Die Voraussetzungen sind ein gutes Design der multidimensionalen Datenbank und effizient geschriebene MDX-Kalkulationen.
Bei kleinen Cubes ist die Performance von Abfragen ohne weiteres Zutun sehr gut. Aber was passiert, wenn Dutzende Millionen Fakten im Cube vorhanden sind? Man kann sofort sehen, dass sich die Ausführungszeiten von Abfragen logischerweise verschlechtern. Kann mit einfachen Mitteln ein großer Cube ebenfalls eine gute Performance erreichen, die mit der von kleineren Cubes vergleichbar ist? Die Antwort lautet Ja – mit der Erstellung von Aggregationen in Analysis Services für große Cube-Partitionen.
Was verbirgt sich hinter diesen Aggregationen? Nehmen wir als Beispiel einen einfachen Cube mit der folgenden Struktur:
- Dimensionen
- Periode (Jahr/Quartal/Monat/Tag)
- Kunde (Region/Gebiet/PLZ/Kunde)
- Produkt (Produkthauptgruppe/Produktgruppe/Produkt)
- Analysewerte
- Umsatz
Die niedrigste Granularität von unserer Measuregroup ist Tag, Kunde, Produkt, d. h. der Analysewert Umsatz wird für jede existierende Kombination Tag, Kunde, Produkt im Würfel gespeichert. Was passiert, wenn die Umsätze für höhere Granularitäten, z. B. für bestimmte Monate, Gebiete, Produktgruppen abgefragt werden? Man kann es mit den folgenden Schritten verdeutlichen.
Erste Ausführung einer Abfrage für eine bestimmte Kombination Monat, Gebiet, Produktgruppe: Die angeforderten Daten sind noch nicht im SSAS-Cache vorhanden. Der Cube hat die Daten auf der Granularitätsebene für Tag, Kunde und Produkt gespeichert, deshalb liest SSAS die Daten auf dieser Granularitätsebene aus. Im zweiten Schritt werden die Daten auf Monat, Gebiet und Produktgruppe aggregiert – für große Partitionen sind entsprechende CPU-, Arbeitsspeicher- und Plattenressourcen notwendig und die Ausführung der Abfrage kann eine Weile dauern. Das Abfrageergebnis wird der Client-Software weitergeleitet und im SSAS-Cache gespeichert.
Bei der zweiten Ausführung der Abfrage für obiges Beispiel: Die angeforderten Daten sind schon im SSAS-Cache, deshalb werden sie direkt aus dem Cache gelesen und der Client-Software weitergeleitet. Folgende Punkte sollte man beachten:
- Anzahl von möglichen Kombinationen von Dimensionsebenen und -Elementen, die abgefragt werden können. Bei einer großen Anzahl der Dimensionen, Dimensionselementen und Usern ist diese sehr groß und fast für jeden Anwender unikal. Es wird ziemlich lange dauern, bis der Cache mit den aggregierten Daten gefüllt wird.
- Der SSAS-Cache ist nicht persistent. Bei jedem Neustart von SSAS oder nach jeder Würfelverarbeitung wird der Cache geleert und muss dann durch Userabfragen neu befüllt werden. Hier werden wieder Serverressourcen verschwendet.
- Wenn ein dynamisches Sicherheitskonzept in SSAS-Rollen verwendet wird, dann hat jede Rolle seinen eigenen Cache.
Wenn Aggregationen angelegt werden sollen, wie geht man am besten vor? Woher weiß man, für welche Kombinationen von Dimensionen und Dimensionsebenen die Aggregationen erstellt werden sollen? Schon für unser einfaches Beispiel gibt es 4 (Periode) x 4 (Kunde) x 3 (Produkt) – 1 (die Granularitätsebene) mögliche Aggregationen. Die Antwort lautet: Usage-Based Aggregations – Aggregationen, die auf den ausgeführten Abfragen berechnet werden.
Im Folgenden wird aufgezeigt, wie solche Aggregationen erstellt werden können und welche Vorteile diese bringen. Als Beispielsystem wird eine OLAP-Datenbank mit mehreren Millionen Datensätzen in den Faktentabellen verwendet. Nur bei solchen Datenmengen ist es sinnvoll, die Aggregationen zu erstellen – für kleinere Cubes bringen die Aggregationen keinen sichtbaren Vorteil.
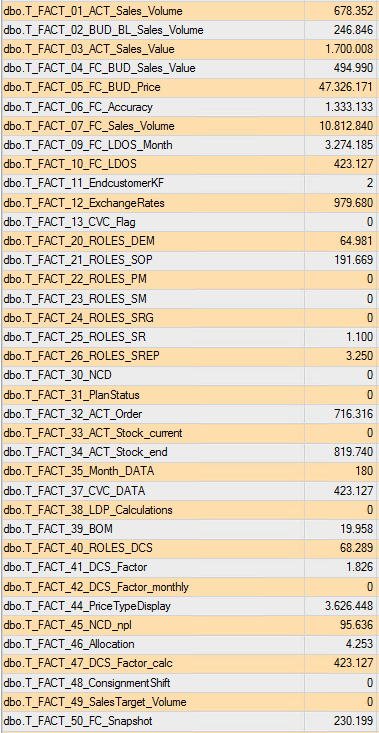
Abbildung 1: Anzahl Datensätze in den Faktentabellen
Um die Informationen über die auf dem OLAP-Server ausgeführten Abfragen zu sammeln, muss das Query Log in den Servereigenschaften von SSAS aktiviert werden.
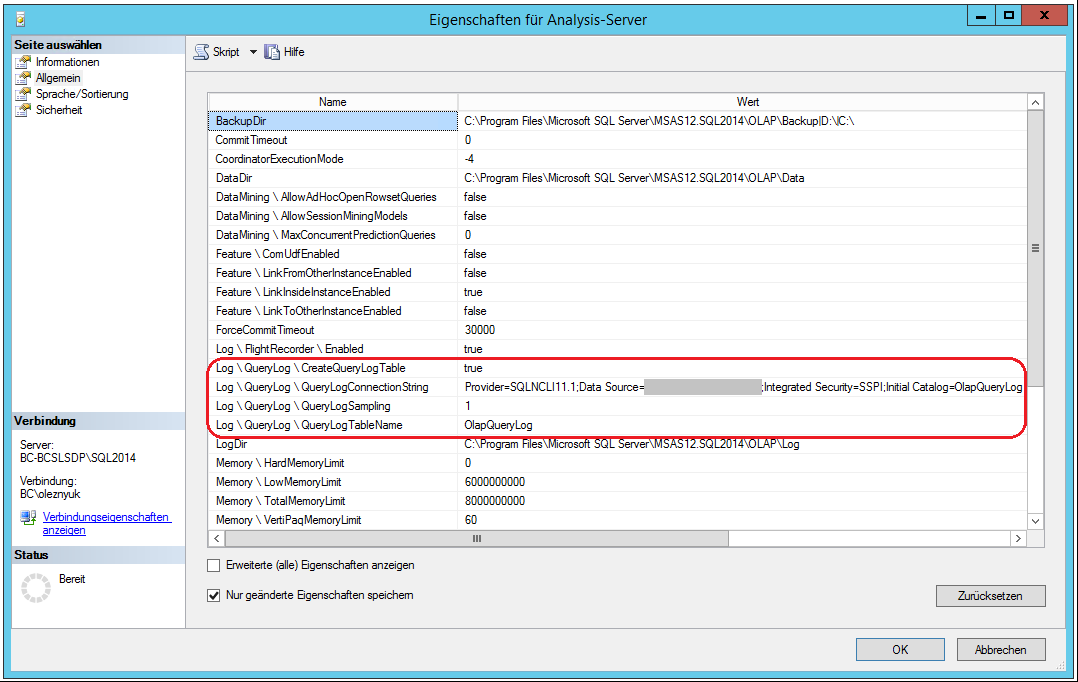
Abbildung 2: Aktivierung vom Query Log in SSAS
Der Parameter QueryLogSampling wurde auf 1 gesetzt, da im Beispiel nur ein einziger User im System arbeitet. In Systemen, die von mehreren Usern verwendet werden, ist es ratsam, die Standardeinstellung von 10 zu verwenden, damit das Query Log nicht so schnell wächst.
Jetzt sollten möglichst viele für das System typische Berichte mit Hilfe von DeltaMaster ausgeführt werden – damit wird das Query Log mit Abfragedaten gefüllt, auf deren Basis die Aggregationen berechnet werden.
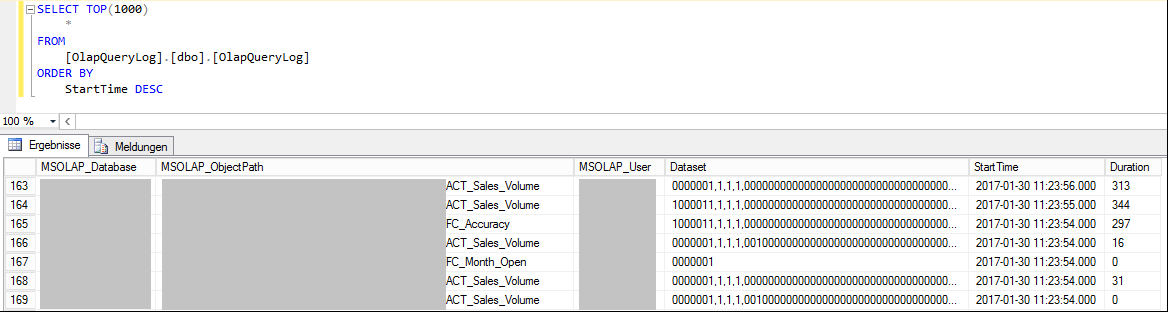
Abbildung 3: Inhalte vom Query Log
Sobald das Query Log gefüllt ist, kann man mit dem Design der Usage-Based-Aggregationen anfangen. Für das einfache und effiziente Design der Aggregationen wird das Visual Studio Add-In BIDS Helper notwendig: http://bidshelper.codeplex.com. Die Dokumentation für Aggregation Manager findet man hier: http://bidshelper.codeplex.com/wikipage?title=Aggregation%20Manager&referringTitle=Documentation.
Zuerst wird ein neues Analysis Services-Projekt in SQL Server Data Tools vom Typ „Von Server importieren“ erstellt und im Arbeitsverzeichnis gespeichert.
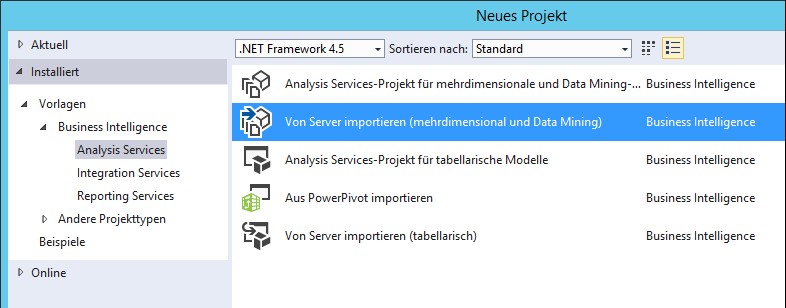
Abbildung 4: Neues SSAS-Projekt
In einem Würfel im Reiter „Partitionen“ sieht man auf der Toolbar drei neue Buttons, die von BIDS Helper hinzugefügt wurden:
- Update All Estimated Counts
- Edit Aggregations
- Deploy Aggregation Designs
Damit die Aggregationen die Distribution der Daten in den Dimensions-Attributhierarchien und in den Measure Group-Partitionen berücksichtigen, sollen alle EstimatedRows-Eigenschaften im Projekt aktualisiert werden. Dafür verwendet man den Button „Update All Estimated Counts“.

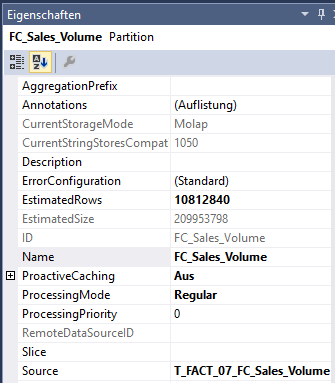
Abbildung 5: Update All Estimated Counts
Jetzt kann mit dem Design der Aggregationen angefangen werden. Dafür wählt man „Design Aggregations“.

Abbildung 6: Design Aggregations
Basierend auf der Anzahl der Datensätze in den Partitionen und auf den Kenntnissen welche Berichte und Kennzahlen am meisten verwendet werden, wurden die folgenden Partitionen für das Design der Aggregationen gewählt:
- ACT_Sales_Volume
- BUD_BL_Sales_Volume
- ACT_Sales_Value
- FC_BUD_Sales_Value
- FC_BUD_Price
- FC_Sales_Volume
- PriceTypeDisplay
Im Aggregation-Manager-Fenster wählt man mit der rechten Maustaste den Ordner „Aggregation Designs“ der Measure Group, für die die Aggregationen erstellt werden sollen und selektiert „Add from Query Log…“.
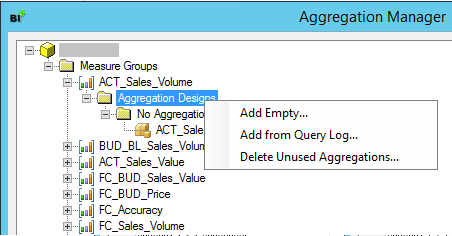
Abbildung 7: Add from Query Log
Im „Add Aggregations From Query Log…“-Fenster müssen die folgenden Parameter angepasst werden bevor man auf „Execute SQL“ drückt:
- Aggregation Design Name. Diesen Namen sieht man später in BIDS Helper und SQL Server Management Studio (kurz: SSMS), deshalb ist es sinnvoll die sprechenden Namen zu verwenden. Die folgende Namenskonvention ist empfohlen: BC_<Measure Group Name>_<xx Version>.
- Aggregation Prefix. Die Benennung wie beim Aggregation Design Name mit Unterstrich am Ende. Diesen Namen sieht man später in SQL Server Profiler (kurz: Profiler).
- SQL Query. Hier ist es ratsam die WHERE-Bedingung für „duration“ anzupassen. Für unser Beispiel wurde 0 gewählt (alle Abfragen), aber diese Einstellung ist systemspezifisch – die Standardeinstellung ist 100.
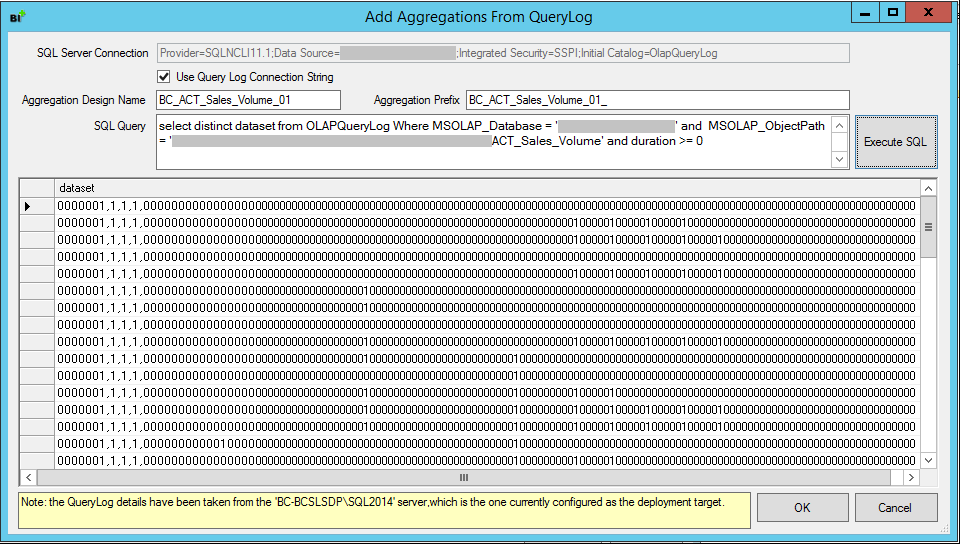
Abbildung 8: Add Aggregations From Query Log Einstellungen
Nachdem das Aggregationsdesign gespeichert wurde, kann man es anschauen und editieren. Die folgenden zwei Optionen sind beim Editieren sehr wichtig:
- Eliminate Redundancy
- Eliminate Duplicates
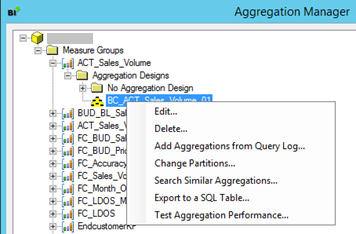
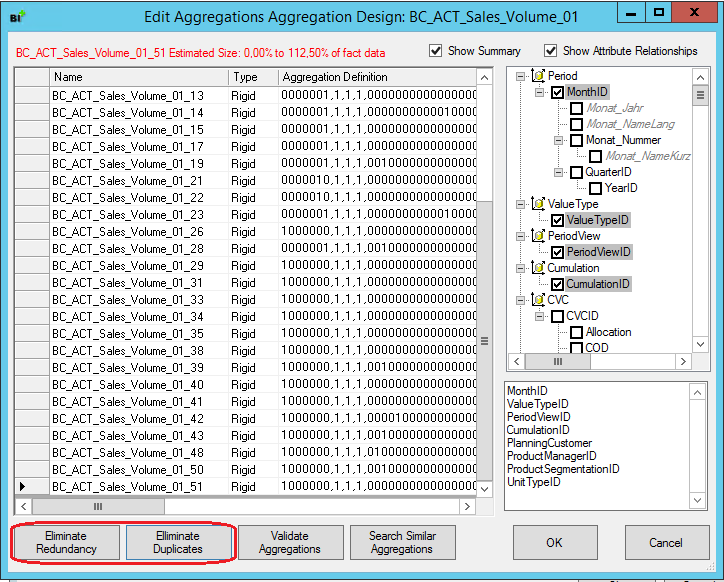
Abbildung 9: Edit Aggregation Design
Nach dem Editieren wird das Aggregationsdesign den Partitionen zugewiesen – dafür wählt man „Change Partitions…“ aus dem Kontextmenü.
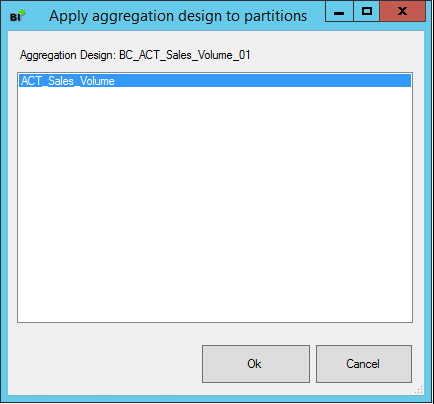
Abbildung 10: Apply aggregation design to partitions
Um das Aggregationsdesign zu testen, kann man „Test aggregation performance…“ aus dem Kontextmenü wählen.
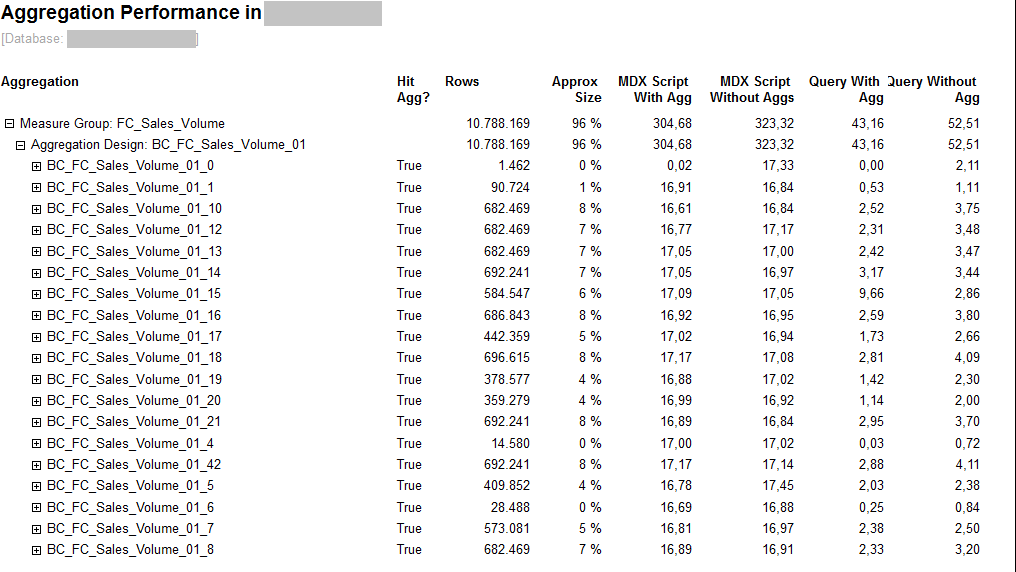
Abbildung 11: Test aggregation performance
Aus dem Bericht kann man sehen, dass für die meisten Testabfragen (außer einer) die Abfragen mit Aggregationen eine bessere Performance zeigen. Aber das sind Testabfragen – wie die Performance mit den Abfragen im Echtsystem aussieht, wird man später sehen.
Nachdem alle Aggregationsdesigns erstellt wurden, muss das Projekt deployt werden. Nach dem Deployment kann man die Aggregationen in Management Studio verwalten und skripten.
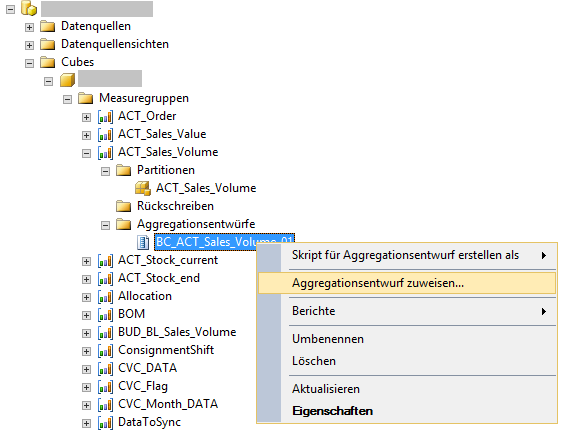
Abbildung 12: Verwaltung der Aggregationen in Management Studio
Die Aggregationen sind jetzt auf dem Server und die Performance von DeltaMaster-Berichten kann für die folgenden Szenarien getestet werden:

Abbildung 13: Testszenarien
Für jedes Testszenario wird jeder Testbericht dreimal ausgeführt.
Die Aggregations-Partitionszuweisung und Entfernung der Zuweisung kann in SSMS getätigt werden (vgl. Abbildung 12).
Der SSAS-Cache wird mit dem folgenden XMLA-Befehl geleert:

Für die Analyse der Ausführung von den Testabfragen startet man SSAS-Profiler mit den folgenden Parametern:
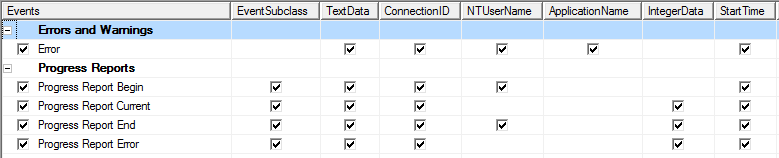

Abbildung 14: Profiler-Parameter
Die Ablaufverfolgung für eine Abfrage ohne Aggregationen sieht so aus:

Abbildung 15: Ablaufverfolgung ohne Aggregationen
Und mit Aggregationen kann man in der Ablaufverfolgung sehen, dass die Aggregationen wirklich verwendet werden:
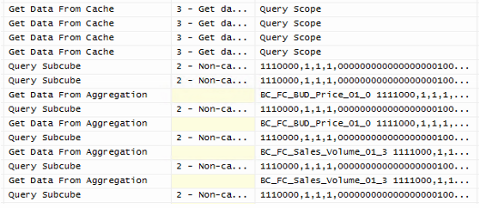
Abbildung 16: Ablaufverfolgung mit Aggregationen
Für die Analyse der Testergebnisse wurde die Datenbank DeltaMaster_AggregationPerformance erstellt. Die Testergebnisse sehen so aus:
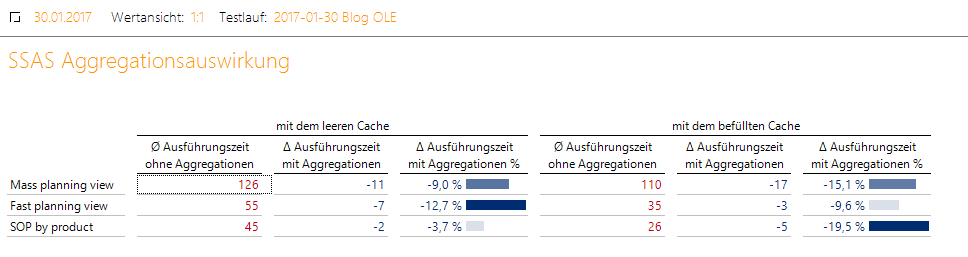
Abbildung 17: Testergebnisse
Aus den Testergebnissen kann man sehen, dass die Erstellung von den Usage-Based-Aggregationen sichtbare Performance-Vorteile gebracht hat. Diese Aggregationen sind relativ klein und werden schnell verarbeitet, die Erstellung ist sehr einfach, sie bringen nur Vorteile und sind bei großen Partitionen im Millionenbereich empfehlenswert.
