Nachdem bereits ein Non-Vanilla-Weg zum inkrementellen Laden von Daten aufgezeigt wurde (Blogbeitrag „Inkrementelles Laden mit relationaler Partitionierung“), treten wir heute nochmal einen Schritt zurück und zeigen die Grundzüge eines einfachen inkrementellen Szenarios und erläutern dabei ausführlich die notwendigen Kniffe im Modeler. Aufgrund der zahlreichen Fragen in jüngster Vergangenheit, scheint hier noch etwas Grundlagenarbeit nötig zu sein – also ab in die Vanilla-Welt!
Unter der Haube
Treten wir zunächst einmal einen Schritt zurück und stellen ein paar grundsätzliche Überlegungen zum inkrementellen Laden und der zugehörigen Partitionierung an. Ein inkrementelles Ladeszenario wird man in der Regel nur dann wählen, wenn die Ladeperformance eines BI-Systems zu schlecht ist oder wenn man selbiges erwartet. Die optimale Performance wird man bei gleichzeitiger Partitionierung auf relationaler Ebene erreichen. Eine Partitionierung ist aber nicht nur auf der relationalen Ebene von Relevanz. Auch in der OLAP-Datenbank kann eine Partitionierung Performancevorteile bringen. Dort sogar an zwei Stellen: beim Aktualisieren der Daten und beim Abfragen der Daten. Von daher gibt es verschiedene Partitionierungsszenarien in einer BI-Architektur, die verschiedene Vor- und Nachteile haben:
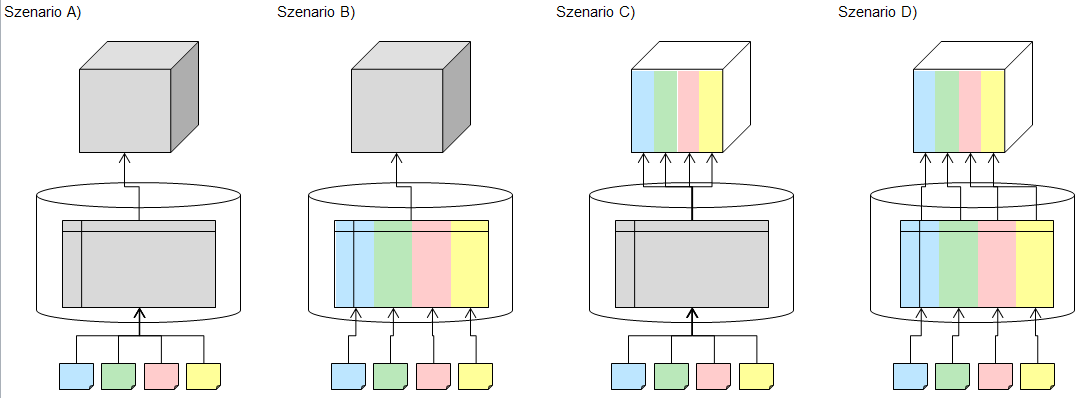 Abbildung 1: Übersicht Partitionierungsszenarien
Abbildung 1: Übersicht Partitionierungsszenarien
Bei Szenario A werden unterschiedliche „Quelldatenhäppchen“ in eine große Tabelle geladen und von dort in eine Würfelpartition weiterverarbeitet. Die Häppchen können hier zwar einzeln geladen werden, da aber immer in die „große“ Tabelle importiert wird, muss man Abstriche bei Ladezeit und Speicherbedarf (insbesondere in dem Transaction Log) in Kauf nehmen. Dafür ist der Aufbau des Szenarios denkbar einfach und mit wenig Pflegeaufwand verbunden.
Szenario B nutzt auch die vollen relationalen Partitionierungsmöglichkeiten. Im Prinzip könnte man hier noch zwei Varianten unterscheiden: Eine, in der echte Tabellen existieren (wie es der Modeler bei eingeschalteter Partitionierung macht) und eine, in der lediglich eine Tabelle über eine relationale Partitionierung aufgeteilt wird. In beiden Fällen münden die relationalen Partitionen in einem unpartitionierten Würfel. Hier wird die Ladeperformance noch einmal verbessert, da (insbesondere bei der im genannten Beitrag beschriebenen SWITCH-Technik) das Transaction Log komplett umgangen wird. Die Aufbereitung des Würfels und die Abfragen würden allerdings immer noch stets den kompletten Datenbestand umfassen. Da hier recht wenig Implementierungsaufwand enthalten ist, sollte der fehlende Schritt hin zu Szenario D grundsätzlich empfohlen werden.
Szenario C wird insbesondere für die Optimierung von MDX-Abfragen herangezogen und kann über dynamische Partitionen direkt im BIDS konfiguriert werden. Die relationale Grundlage ist wie bei Szenario A eine große Tabelle. Durch die Partitionierung des Würfels kann lediglich die Analysis Services Engine die Abfragen besser optimieren. Ganz einfach gesprochen, kann hier bei einer Abfrage entschieden werden, in welcher Partition die notwendigen Daten zu finden sind, so dass bei der Interpretation nicht alle Daten sondern nur die benötigten herangezogen werden müssen. Also wenn z. B. nur Daten vom aktuellen Jahr abgefragt werden, kann AS genau in den richtigen Datentopf greifen. Allerdings halten wir auch hier den weiteren Schritt hin zu Szenario D für sinnvoll, da in dem oben genannten Fall auch wirklich nur ein kleiner relationaler Datentopf abgefragt wird.
Szenario D ist die volle Ausbaustufe mit relationaler und multidimensionaler Partitionierung. Hier ist die maximale Performance auf Lade- und Abfrageseite zu erwarten, allerdings auch der größte Implementierungsaufwand. Insbesondere wenn man mit der „echten“ SWITCH-Logik arbeitet. Eine einfache Variante der Partitionierung wird auch vom Modeler unterstützt. Hier müssen die Partitionen allerdings in regelmäßigen Abständen wieder angepasst werden (z. B. bei Jahreswechseln). Aber was nicht ist, kann ja noch werden!
Für den folgenden Beitrag konzentrieren wir uns auf die vom Modeler unterstützte einfache Variante von Szenario D, bei der pro Jahr eine relationale wie multidimensionale Partitionierung vorgenommen wird. Die Zuordnung der Quelldaten zu den relationalen Tabellen ist dabei statisch und wird nicht „geswitcht“. Um die Problematik der regelmäßigen Anpassung etwas zu mildern, legen wir in der Praxis meist viele Partitionen für die Zukunft „auf Halde“ an, so dass erst in einigen Jahren wieder angepasst werden muss. So sehen wir beispielsweise Partitionen von 2010 bis 2025 vor, bei denen jeweils eine Quelltabelle dahinter liegt. Die Zukunftspartitionen laufen dann einfach so lange leer mit, bis das Jahr erreicht ist. Wenn wir dann ohnehin mal wieder am System arbeiten, können neue Partitionen ergänzt werden.
Modeler explained
Wie bereits oben erwähnt, unterstützt der Modeler eine einfache Variante von Szenario D. Hier werden einfach getrennte Quelltabellen für die MeasureGroups konfiguriert und anschließend definiert welche dieser Quelltabellen tatsächlich gelöscht und/oder geladen werden sollen. Hierbei sind verschiedene Flags relevant, die von der Modeler-Ladelogik interpretiert werden. Schauen wir uns die Konfiguration im Detail an.
Konfiguration der Quelltabellen
Zunächst brauchen wir für unsere MeasureGroup pro zu landendem Jahr eine Quelltabelle. Da wir in der Regel mit Views arbeiten, empfiehlt es sich auch hier pro Jahr eine View anzulegen. Damit einen die lästige Fleißarbeit nicht in den Wahnsinn treibt und weil der Modeler, wie bereits ein-, zweimal erwähnt, ein „echter Kumpel“ ist, gibt es dafür eine Metaprozedur, die uns die Views pro Jahr anlegt. Man gibt lediglich Name der Quelltabelle (oder –view) an, die Spalte, in der die Jahres-zahl zu finden ist, sowie das gewünschte Start- und Endjahr – fertig. Der Aufruf sieht folgendermaßen aus:
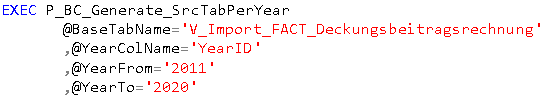
Anschließend müssen die Quelltabellen nur noch im Modeler als Quelle konfiguriert werden, wobei ein weiterer Kniff im Modeler hier hilft Konfigurationsarbeit zu sparen:
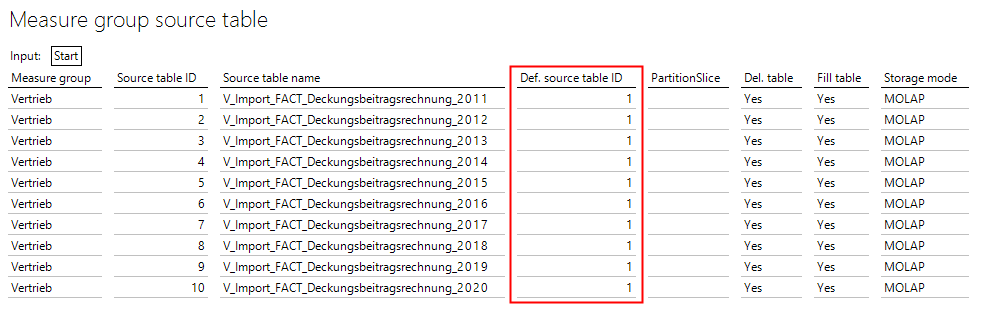 Abbildung 2: Konfiguration “Def. source table ID” in Bericht „Measure group source table”
Abbildung 2: Konfiguration “Def. source table ID” in Bericht „Measure group source table”
Über den Parameter „Def. source table ID“ kann sich der Modeler einfach bei einer anderen Quelltabelle die Spaltenkonfiguration abschauen. Sprich, wir müssen nicht für alle 10 Quelltabellen die Spaltennamen der Dimensionen und Kennzahlen zuordnen, sondern lediglich einmal. Bei allen anderen Quelltabellen verweisen wir einfach auf die erste Quelltabelle. Fertig!
Aktivierung der Partitionierung
Der entscheidende Schalter, um die Partitionierung zu aktivieren, versteckt sich im „normalen“ MeasureGroups-Bericht:
 Abbildung 3: Konfiguration „Partition per src.tab.“ in Bericht „Measure groups“
Abbildung 3: Konfiguration „Partition per src.tab.“ in Bericht „Measure groups“
Mit „Partition per src.tab.“ kann man den Modeler dazu bewegen pro Quelltabelle eine Partition zu erzeugen. Das macht er dann grob nach Szenario D, wobei er relational mit „echten“ Tabellen arbeitet und nicht mit dem Partition-Switching. Ist der Schalter aktiviert, wird pro Quelltabelle eine P_FACT-Routine erstellt (was sich nicht zum Standardverhalten unterscheidet) plus eine T_FACT-Tabelle pro Quelltabelle sowie eine MeasureGroup-Partition pro Quelltabelle. Die Objekte erhalten als Suffix dann einfach einen fortlaufenden Index.
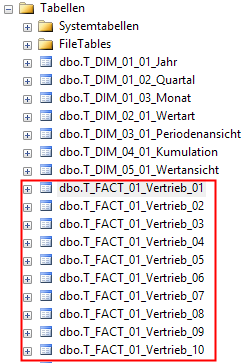
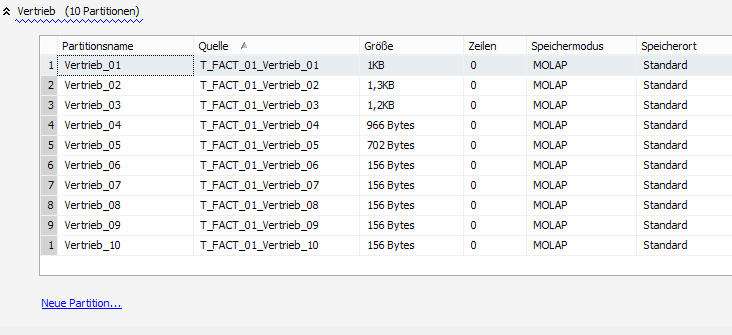 Abbildung 4: Ergebnis der Modeler-Partitionierung in RDB und OLAP-DB
Abbildung 4: Ergebnis der Modeler-Partitionierung in RDB und OLAP-DB
Übrigens hilft einem der Modeler auch beim späteren Umgang mit den aufgeteilten Fakten. Will man relational auf alle Vertriebsdaten zugreifen, müsste man je nach Jahr jetzt auf andere Objekte zugreifen. Um dies zu vereinfachen, legt der der Modeler extra einen UNION-View an, in der alle Partitionen wieder summiert dargestellt werden. Ihr Name in unserem Beispiel: V_FACT_UNION_01_Vertrieb.
Clap-on Clap-off
Jetzt ist es ja schon einmal gut, dass wir die Daten in unterschiedliche Partitionen aufgeteilt haben. Inkrementell ist das Ganze allerdings noch mitnichten. Dafür fehlen uns zwei weitere Parameter: „Del. table“ und „Fill table“. Diese steuern, ob die Partitionen beim Ausführen der Transform-All-Routine gelöscht und/oder gefüllt werden. Beides ist getrennt steuerbar, zum Beispiel für den Fall, dass jeden Tag neue Daten in eine Partition hinzukommen („Fill table“ = Yes), die bereits an den Vortagen importierten Daten aber nicht neu geladen werden sollen („Del. table“ = -).
Das Tolle an den beiden Parametern ist, dass diese ohne die Ausführung des Create-Snowflake-Prozesses greifen. Sprich, direkt nachdem sie in der Modeler.das umgestellt wurden, sind sie beim nächsten Transform-All wirksam. Wie das geht? Ganz einfach mal einen Blick in die P_FACT-Routinen werfen, dort wird das Geheimnis gelüftet:
 Abbildung 5: Kopfbereich einer P_FACT-Prozedur
Abbildung 5: Kopfbereich einer P_FACT-Prozedur
Seit der Modeler-Version 212 wird die Befüllung der Fakten nur unter gewissen Bedingungen ausgeführt. Die entsprechend gesetzten Parameter sind eine davon.
Mit diesem Wissen ist es nun auch möglich ein dynamisches Szenario der Befüllung zu implementieren. Abhängig von dem aktuellen Jahr könnte man nun einfach die beiden Parameter per Update anpassen und im nächsten Ladelauf würden nur noch die aktuellen Partitionen neu befüllt werden. Das Update muss dabei einfach auf der Tabelle T_Model_…. Moment, wo eigentlich ausgeführt werden?
Genau hier liegt ein häufiger Grund für Verwirrung bei der Konfiguration des Modelers. Die Parameter „Del. table“ und „Fill table“ existieren nämlich zweimal in den Berichten der DAS-Datei. Zum einen im Bericht „Measure groups“:
 Abbildung 6: Konfiguration „Del. table“ und „Fill table“ in Bericht „Measure groups“
Abbildung 6: Konfiguration „Del. table“ und „Fill table“ in Bericht „Measure groups“
Zum anderen im Bericht „Measure group source table“:
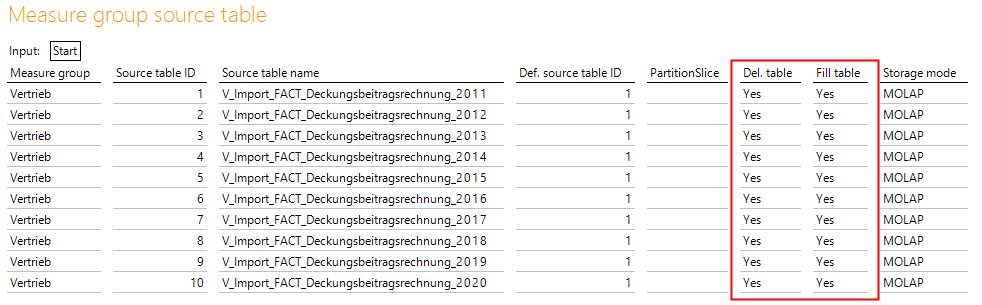 Abbildung 7: Konfiguration „Del. table“ und „Fill table“ in Bericht „Measure group source table“
Abbildung 7: Konfiguration „Del. table“ und „Fill table“ in Bericht „Measure group source table“
Und welcher Parameter wird nun verwendet? Ganz einfach – wenn „Partition per src.tab.“ auf YES steht, werden die Parameter des Berichts „Measure group source table“ verwendet. Ansonsten die Parameter des Berichts „Measure groups“. Der Grund liegt auf der Hand – wenn pro Quelltabelle partitioniert werden soll, muss es auch möglich sein für jeden Partition getrennt zu entscheiden, ob diese gelöscht und/oder gefüllt werden soll oder nicht. Andernfalls hätte die Partitionierung keinen Sinn. Soll nicht partitioniert werden, genügt eine globale Einstellung für die ganze MeasureGroup.
Blick in die Sterne
Das ist schon der ganze Zauber der einfachen Partitionierung und inkrementellen Befüllung im Modeler 212. Diese hat natürlich auch ein paar Nachteile, die im früheren Beitrag bereits beschrieben und mit seinem Verfahren umgangen hat.
Sicher ist jetzt schon, dass in der Version 213 noch eine weitere Unterstützung für inkrementelle Szenarien ausgeliefert wird. Dann nämlich, wenn im Modell etwas grundsätzlich umgebaut oder erweitert wird. Der notwendige Create-Snowflake-Prozess löscht heute die kompletten Tabelleninhalte wenn man sich nicht zuvor darum per Backup und Restore kümmert. Im Modeler 213 wird es ein inkrementelles Snowflake geben, welches nur die geänderten und die davon abhängigen Objekte ändert. Wird also beispielsweise eine neue Measure in einer Faktentabelle ergänzt, werden alle anderen Faktentabellen nicht neu erstellt. Damit entfallen viele Wartezeiten bei der Projektentwicklung. Das geht sogar so weit, dass es ein Non-Vanilla-Pro-Feature geben wird, nennen wir es mal Hot-Chili-Feature. In der 213 wird man ein Create-Snowflake komplett simulieren können, ohne dass SQL-Objekte verändert werden. Es wird lediglich der neue Quellcode der Objekte erzeugt und der kundige BI-Berater kann den Code anschließend nach Belieben verwenden und per chirurgischem Kleineingriff in sein System einbauen.
